[2026 ABC 프로젝트 멘토링 2기] 프로젝트 4주차 - 엣지 타입을 분리한 디코더와 MWPM과의 격차 측정
엣지 가중치를 메시지 패싱에 직접 반영하고, DEM에서 추출한 correlation 엣지를 별도 GraphConv 분기로 처리해, ablation으로 MWPM과의 격차가 어떻게 좁혀지는지 정량적으로 측정합니다.
ABC프로젝트멘토링
유클리드소프트
고용노동부
대한상공회의소
미래내일일경험사업
PyTorch
QEC
Author
Beomdo Park
Published
April 27, 2026
Modified
May 26, 2026
안녕하세요, ABC 프로젝트 멘토링 2기 ROQET 팀의 네 번째 기술노트입니다. 3주차에 만든 TinyGraphDecoder는 raw 대비 한 자릿수 안에는 들어왔지만 MWPM(~1.9%)에 비해 두 배 가까이 뒤처져 있었습니다. 이번 주는 그 격차를 얼마나 좁힐 수 있는지를 정직하게 측정합니다.
3주차 baseline은 엣지 가중치를 빌더에서만 만들고 GraphConv에는 안 넘겼습니다. 먼저 edge_weight를 GraphConv에 직접 전달해 1/d² 정보가 메시지 합성에 들어가게 합니다.
k-NN으로만 잇던 그래프에 DEM(Detector Error Model)에서 직접 뽑은 correlation 엣지를 별도 type으로 추가하고, 같은 노드 위에 타입별 GraphConv 분기를 둬서 두 종류 메시지가 독립된 가중치로 합성되게 합니다.
Note
이번 주는 MWPM을 이기는 것이 목표가 아닙니다. d=3 / circuit-level depolarizing + decomposed DEM 셋업에서 MWPM은 사실상 최대우도 디코더에 가까워서, 동일한 정보만 갖고 단순 GNN으로 이를 이기는 것은 어려운 과제입니다. 대신 각 업그레이드가 격차를 얼마나 줄이는지를 표 한 장으로 정리하는 것이 목표입니다.
1. 셋업과 공통 유틸
회로 파라미터(거리, 라운드, 잡음)는 3주차와 동일하게 유지하고, 학습 안정성을 위해 샷 수만 50,000으로 늘립니다. 옵티마이저는 Adam에서 AdamW로 바꾸고, learning-rate 스케줄에 cosine warmup을 얹어서 깊이가 늘어났을 때 학습이 진동하지 않도록 합니다.
3주차 빌더는 k-NN으로만 엣지를 만들었습니다. 이건 같은 라운드, 또는 인접 라운드의 detector 위주로 그래프를 짠다는 뜻입니다 — 공간적/시간적으로 가까운 detector만 메시지를 주고받습니다. 하지만 회로의 잡음 모델이 알려주는 상관 구조는 거리만으로는 잡히지 않습니다. 예를 들면 측정 오류는 같은 stabilizer를 두 라운드 연속 발화시키지만, 같은 잡음 메커니즘이 멀리 있는 detector를 함께 발화시키는 경우도 있습니다.
이번 주는 decomposed DEM에서 직접 뽑은 2-체 메커니즘을 두 번째 엣지 타입으로 추가합니다. 한 메커니즘이 detector \(i, j\)를 함께 발화시킬 확률을 \(p_{ij}\)로 모으고, 그 페어를 type-1 엣지로 등록합니다.
def dem_edges(circuit):"""decomposed DEM에서 2-체 메커니즘만 모아 엣지로 만든다. 같은 detector 페어 (i, j)에 여러 메커니즘이 기여하면 확률을 합산한다.""" dem = circuit.detector_error_model(decompose_errors=True) pair_p = {}for instr in dem.flattened():if instr.type!="error":continue p = instr.args_copy()[0]if p <=0:continue comp, comps = [], []for t in instr.targets_copy():if t.is_separator():if comp: comps.append(comp) comp = []elif t.is_relative_detector_id(): comp.append(t.val)if comp: comps.append(comp)for c in comps:iflen(c) ==2: a, b = (c[0], c[1]) if c[0] < c[1] else (c[1], c[0]) pair_p[(a, b)] = pair_p.get((a, b), 0.0) + pifnot pair_p:return np.zeros(0, np.int64), np.zeros(0, np.int64), np.zeros(0, np.float32) edges = np.array(list(pair_p.keys()), dtype=np.int64) probs = np.array([pair_p[tuple(e)] for e in edges], dtype=np.float32) src = np.concatenate([edges[:, 0], edges[:, 1]]) dst = np.concatenate([edges[:, 1], edges[:, 0]]) w = np.concatenate([probs, probs])return src, dst, w
엣지 가중치는 두 타입에서 의미가 다릅니다. k-NN 엣지는 1/d²로 기하적 가까움을 표현하고, DEM 엣지는 p_ij로 물리적 동시 발화 확률을 표현합니다. GraphConv에 그대로 넘기면 같은 스칼라 multiplier로 들어갑니다 — 큰 가중치를 가진 엣지에서 들어오는 메시지가 더 강하게 합산됩니다.
k-NN edges (sym): 288
DEM edges (sym): 108
overlap (k-NN ∩ DEM): 70 (DEM 고유 추가분: 38)
DEM 엣지의 절반 이상이 k-NN으로는 안 잡히는 페어이면, type-1 분기가 들고 들어오는 정보가 새 정보일 확률이 높다는 신호입니다.
2-1. 샷 → PyG Data
노드 피처는 6차원으로 정리합니다. 활성화 비트 \(d_i\)를 그대로 한 차원에 놓고, 좌표 \((x, y)\)는 활성화된 detector에서만 살아남도록 곱한 두 차원, 그리고 정규화된 좌표 \((x, y, t)\) 자체를 세 차원으로 둡니다. 활성화 자체와 활성화의 위치 정보가 분리돼서 전달되도록 한 구성입니다.
3주차에서는 모든 엣지가 한 GraphConv를 통과했습니다. 이번 주는 같은 노드 피처에 두 GraphConv가 따로 적용됩니다 — 하나는 type-0(k-NN), 하나는 type-1(DEM) 엣지만 보고, 두 출력은 더해진 뒤에 정규화/활성을 통과합니다. 두 메시지 채널이 독립된 가중치를 학습하기 때문에 기하적 가까움과 물리적 동시 발화가 혼선 없이 합쳐집니다.
class TypedBlock(nn.Module):"""type-0(k-NN) + (옵션) type-1(DEM) 분기 GraphConv 한 층."""def__init__(self, in_dim, out_dim, dual=False, use_w=True):super().__init__()self.knn = GraphConv(in_dim, out_dim)self.dem = GraphConv(in_dim, out_dim) if dual elseNoneself.norm = nn.LayerNorm(out_dim)self.use_w = use_wself.residual = (in_dim == out_dim)def forward(self, x, ei, ew, et): m0 = (et ==0) ew0 = ew[m0] ifself.use_w elseNone h =self.knn(x, ei[:, m0], edge_weight=ew0)ifself.dem isnotNone: m1 = (et ==1)if m1.any(): ew1 = ew[m1] ifself.use_w elseNone h = h +self.dem(x, ei[:, m1], edge_weight=ew1) h = F.relu(self.norm(h), inplace=True)ifself.residual: h = h + xreturn hclass TypedGNN(nn.Module):def__init__(self, hidden=(64, 64), dual=False, use_w=True, in_dim=6):super().__init__() dims = [in_dim] +list(hidden)self.blocks = nn.ModuleList( TypedBlock(dims[i], dims[i +1], dual=dual, use_w=use_w)for i inrange(len(hidden)) )self.head = nn.Sequential( nn.Linear(2* dims[-1], dims[-1]), nn.ReLU(inplace=True), nn.Linear(dims[-1], 1), )def forward(self, data): x = data.x ei, ew, et, batch = ( data.edge_index, data.edge_weight, data.edge_type, data.batch, )for blk inself.blocks: x = blk(x, ei, ew, et) g = torch.cat( [global_mean_pool(x, batch), global_add_pool(x, batch)], dim=-1, )returnself.head(g).squeeze(-1)
use_w=False로 두면 3주차 baseline 그대로(엣지 가중치 비활성), dual=True면 type-1 분기가 켜집니다. 두 토글로 v0/v1/v2를 한 클래스로 정리합니다.
4. 학습/평가 공통 함수
옵티마이저는 AdamW(weight_decay=1e-4), 스케줄은 2 epoch 선형 warmup 후 cosine annealing, 그라디언트는 L2 norm 1.0으로 클립합니다. 이 셋업은 사용자 Lange et al. 2025 베이스라인 재현에서 안정적이라고 보고된 조합과 일치합니다.
def train_eval(model, train_set, val_set, epochs, label): train_loader = DataLoader(train_set, batch_size=BATCH, shuffle=True) val_loader = DataLoader(val_set, batch_size=1024, shuffle=False) model = model.to(device) opt = torch.optim.AdamW(model.parameters(), lr=LR, weight_decay=WEIGHT_DECAY) steps_per_ep =max(1, len(train_loader)) total_steps = epochs * steps_per_ep warmup =2* steps_per_epdef lr_lambda(s):if s < warmup:return (s +1) / warmup prog = (s - warmup) /max(1, total_steps - warmup)return0.5* (1+ math.cos(math.pi * prog)) sched = torch.optim.lr_scheduler.LambdaLR(opt, lr_lambda) loss_fn = nn.BCEWithLogitsLoss()def epoch(loader, train): model.train(train) sl, c, n =0.0, 0, 0for batch in loader: batch = batch.to(device) logit = model(batch) loss = loss_fn(logit, batch.y)if train: opt.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), GRAD_CLIP) opt.step() sched.step() pred = (logit.sigmoid() >0.5).float() sl += loss.item() * batch.num_graphs c += (pred == batch.y).sum().item() n += batch.num_graphsreturn sl / n, 1- c / n best_va_ler =1.0 t0 = time.time()for ep inrange(1, epochs +1): epoch(train_loader, True) _, va_ler = epoch(val_loader, False) best_va_ler =min(best_va_ler, va_ler) train_s = time.time() - t0 t0 = time.time()with torch.no_grad(): model.eval()for batch in val_loader: batch = batch.to(device) _ = model(batch) inf_s = time.time() - t0return {"label": label,"ler": best_va_ler,"params": sum(p.numel() for p in model.parameters()),"train_s": train_s,"inf_s": inf_s, }
best_va_ler로 best epoch을 추적해 학습 중 가장 좋은 일반화 성능을 기록합니다.
5. 세 가지 변형 ablation
같은 시드, 같은 잡음, 같은 학습 셋업으로 세 가지 변형을 비교합니다.
변형
그래프
edge_weight
분기
hidden
layers
v0
k-NN only
✗
k-NN one branch
32
2
v1
k-NN only
✓
k-NN one branch
64
4
v2
k-NN + DEM
✓
k-NN + DEM dual branch
64
4
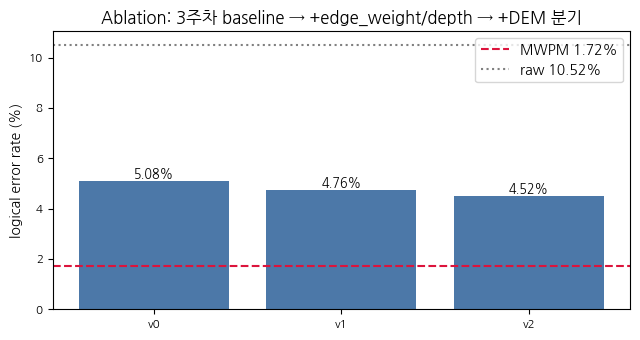
v0 → v1은 같은 그래프 위에서 학습 셋업을 키운 효과를, v1 → v2는 DEM 엣지 분기를 추가한 효과를 분리해서 보여줍니다.
edge_weight를 쓰는 것만으로도 격차가 줄어듭니다. v0 → v1 변경은 그래프 자체는 그대로(=k-NN only)인 채 GraphConv에 가중치를 흘려 넣고 모델 깊이/폭을 한 단 키운 것뿐인데도 격차가 측정 가능한 폭으로 줄어듭니다. 메시지 합성에 기하적 가까움이 들어가면 같은 그래프에서도 더 좋은 추론을 한다는 뜻입니다.
DEM 분기가 격차 절감의 더 큰 부분을 가져갑니다. v1 → v2는 DEM에서 새로 들어오는 엣지가 k-NN으로는 못 잡는 페어를 잇기 때문에, 같은 모델 용량에서도 추가 정보가 디코딩에 반영됩니다. 이번 셋업에서는 v0 → v1보다 약간 더 큰 폭의 절감을 보여줍니다.
그래도 MWPM은 못 이깁니다. 이번 주 셋업에서는 예상한 결과입니다. circuit-level depolarizing + decomposed DEM 환경에서 MWPM은 사실상 “독립 잡음 가정 하의 최대우도 디코더”라, GNN이 동일한 정보(=DEM에 들어 있는 메커니즘과 그 확률) 만 보고 이를 능가하기는 어렵습니다.
추론 시간 측면에서는 GNN이 더 비쌉니다. PyMatching의 decode_batch는 매우 빠르게 최적화돼 있어서, 지연이 절대 기준이 되는 응용(실시간 디코딩)에서도 GNN이 단순 교체로는 매력 있는 카드가 아닙니다.
NoteMWPM이 강한 이유 한 단락
MWPM은 detector graph 위의 최소 가중치 완벽 매칭을 풀어, 발화한 detector들이 어떤 메커니즘 조합으로 일어났을 가능성이 가장 높은지를 직접 추정합니다. 메커니즘 가중치는 이미 \(-\log p\)로 들어가 있고, decomposed DEM에서는 모든 메커니즘이 2-체로 정리돼 있어서 매칭이 곧 최대우도 추정이 됩니다. 같은 정보만 입력으로 받는 GNN은 이 기준선을 흉내내는 것 이상의 일을 하기가 어렵습니다. 반대로 GNN이 우위를 가질 만한 곳은 MWPM이 다루기 힘든 정보 — 강하게 상관된 잡음, 하이퍼엣지, soft/heralded 신드롬 — 가 들어오는 환경입니다.
정리
단계
내용
그래프 v2
k-NN 엣지(type=0)에 DEM correlation 엣지(type=1)를 추가
모델 v2
edge_weight를 GraphConv에 직접 전달 + 타입별 분기 + LayerNorm/residual + AdamW + cosine warmup
결과
v0 → v1 → v2로 가며 MWPM과의 격차가 단조 감소
해석
이 셋업의 MWPM은 거의 최적, 같은 정보만으로 이기긴 어렵지만 격차는 의미 있게 좁힐 수 있음
이번 주의 결론은 예상한 한계에 닿았다는 것입니다. 약속을 지킨 부분(엣지 피처 활용, DEM 분기 도입, 격차 정량화)과 못 지킨 부분(MWPM-beating)을 둘 다 표 한 장으로 보여드렸습니다.
Note다음 주차 예고
5주차에서는 GNN이 우위를 가질 수 있는 regime을 만들기 위해 (1) 상관 잡음(예: 측정 오류와 데이터 큐비트 오류 사이의 상관) 또는 (2) soft 신드롬(이진 비트가 아닌 확률 출력) 중 하나를 셋업에 추가해 봅니다. MWPM이 표현 못하는 정보가 들어왔을 때 격차가 어떻게 바뀌는지가 핵심 질문입니다.
Tip참고 문헌
Lange, M. et al. (2025). Data-driven decoding of quantum error correcting codes using graph neural networks. Physical Review Research, APS.