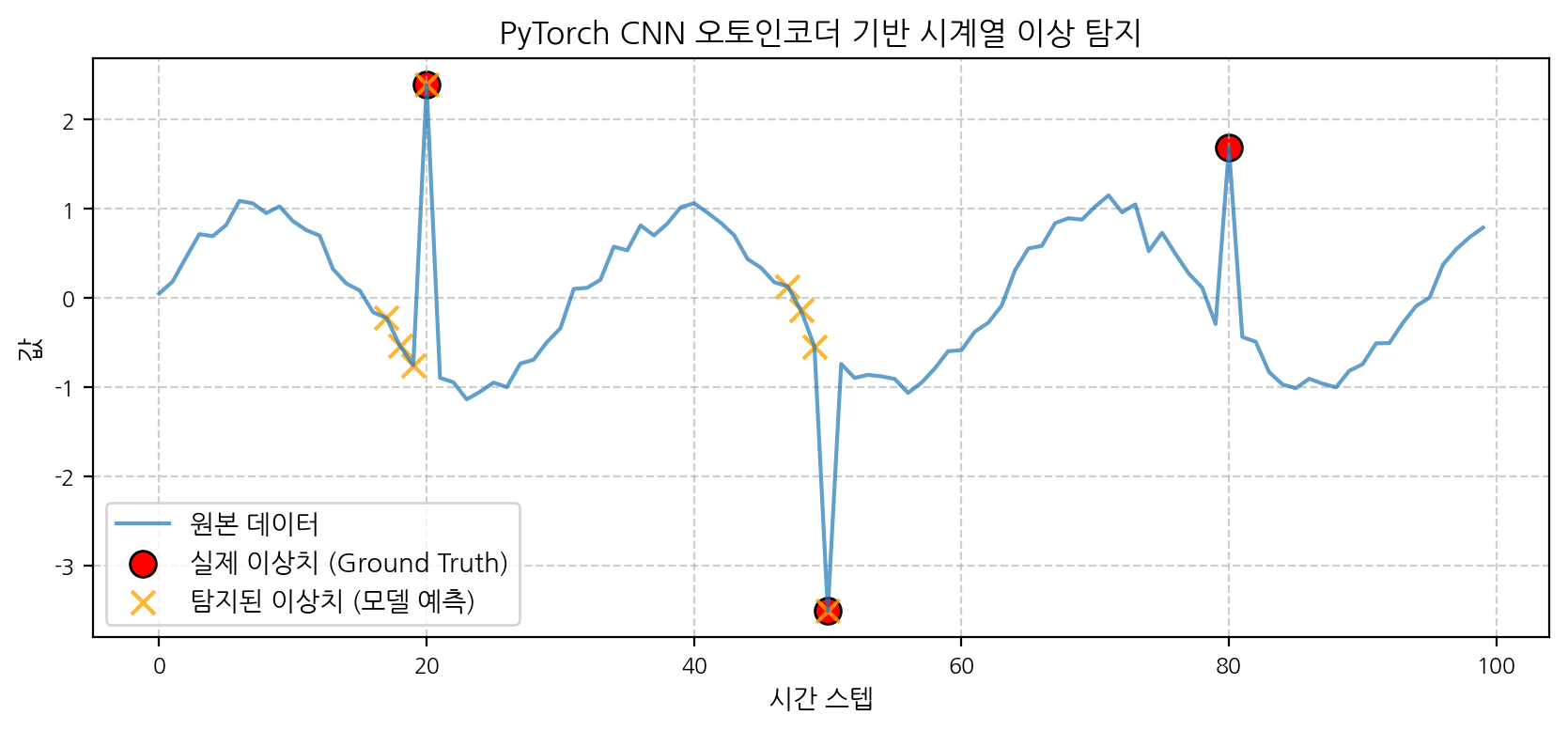
# torch는 cnn-autoencoder-definition 셀에서 이미 import 됨from torch.utils.data import TensorDataset, DataLoader# 정상 데이터로 학습# 'outliers'는 원본 'data' 배열의 인덱스입니다.# 'windows' 배열에서 이상치가 포함된 윈도우를 식별하여 제외합니다.contaminated_window_indices =set()# 'outliers', 'window_size', 'windows' 변수는 이전 셀들에서 정의되어 있어야 합니다.for outlier_data_idx in outliers: start_contaminated_win_idx =max(0, outlier_data_idx - window_size +1) end_contaminated_win_idx = outlier_data_idx for win_idx inrange(start_contaminated_win_idx, end_contaminated_win_idx +1):if win_idx <len(windows): # 윈도우 인덱스가 유효한 범위 내에 있는지 확인 contaminated_window_indices.add(win_idx)normal_windows_mask = np.ones(len(windows), dtype=bool)if contaminated_window_indices: # set이 비어있지 않은 경우에만 인덱싱 normal_windows_mask[list(contaminated_window_indices)] =Falsenormal_windows_np = windows[normal_windows_mask]iflen(normal_windows_np) ==0:print("경고: 학습에 사용할 정상 윈도우가 없습니다. Outlier 정의, window_size 또는 데이터 길이를 확인하세요.")else:# PyTorch 데이터셋 및 로더 준비 normal_windows_torch = torch.tensor(normal_windows_np, dtype=torch.float32) train_dataset = TensorDataset(normal_windows_torch) # 오토인코더는 입력과 타겟이 동일 train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)# 모델 학습 device = torch.device("cuda"if torch.cuda.is_available() else"cpu")print(f"Using device: {device}") model.to(device) epochs =50# 에포크 수 설정 print_every_epochs =10 model.train() # 학습 모드for epoch inrange(epochs): epoch_loss =0for batch_data_list in train_loader: inputs = batch_data_list[0].to(device) targets = inputs # 오토인코더의 타겟은 입력과 동일 optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step() epoch_loss += loss.item() * inputs.size(0) # 배치 손실 누적 (loss.item()은 평균 손실) epoch_loss /=len(train_loader.dataset) # 에포크 평균 손실if (epoch +1) % print_every_epochs ==0:print(f"Epoch [{epoch+1}/{epochs}], Loss: {epoch_loss:.6f}")print("모델 학습 완료.")
Using device: cpu
Epoch [10/50], Loss: 0.485761
Epoch [20/50], Loss: 0.230847
Epoch [30/50], Loss: 0.215341
Epoch [40/50], Loss: 0.208849
Epoch [50/50], Loss: 0.207247
모델 학습 완료.
재구성 오차 계산 및 이상치 탐지
학습된 모델로 데이터를 복원하고, 재구성 오차를 계산합니다:
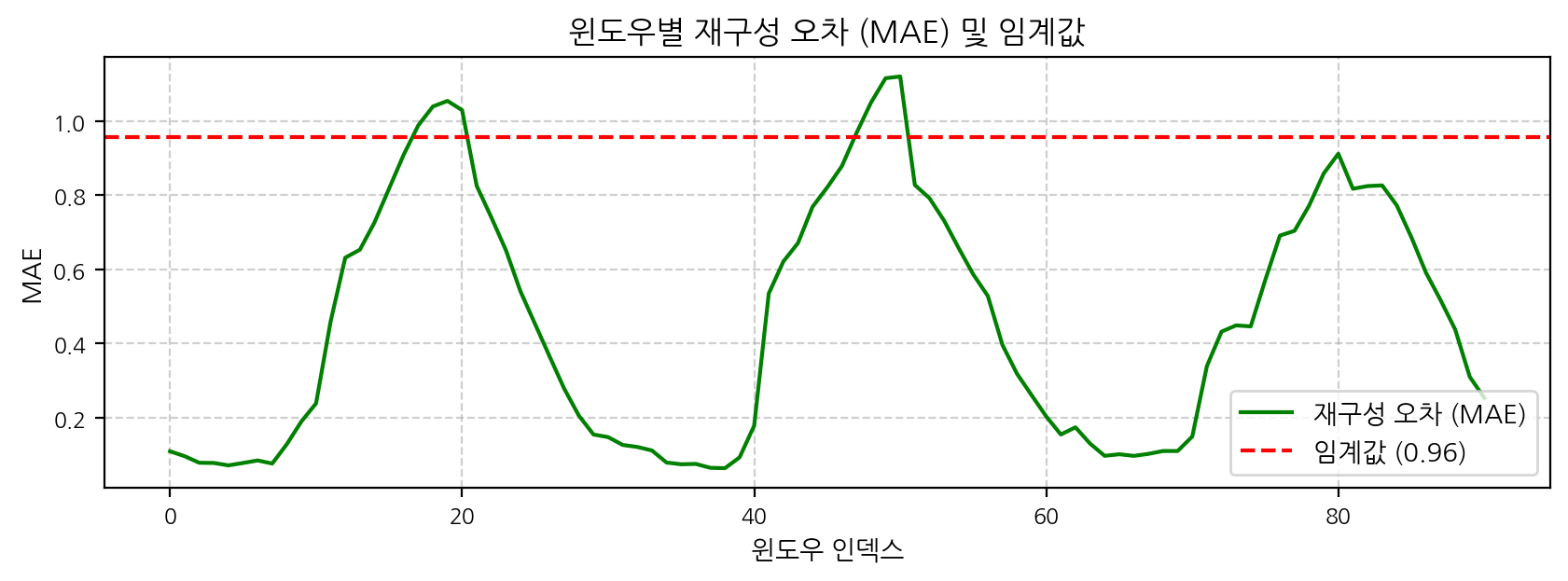
# torch 및 numpy는 이전 셀들에서 이미 import 됨# 재구성 오차 계산device = torch.device("cuda"if torch.cuda.is_available() else"cpu")model.to(device)model.eval() # 평가 모드# 전체 windows 데이터를 PyTorch 텐서로 변환하고 device로 이동all_windows_torch = torch.tensor(windows, dtype=torch.float32).to(device)# 메모리 부족을 방지하기 위해 배치 단위로 처리할 수 있으나, 현재 데이터는 작으므로 한번에 처리with torch.no_grad(): # 그래디언트 계산 비활성화 reconstructed_torch = model(all_windows_torch)# 결과를 CPU로 옮기고 NumPy 배열로 변환reconstructed_np = reconstructed_torch.cpu().numpy()# MAE (Mean Absolute Error) 계산# 원본 windows (numpy 배열)와 reconstructed_np 모두 (N, 1, window_size) 형태# axis=(1, 2)는 채널과 시퀀스 길이에 대한 평균을 의미mae = np.mean(np.abs(windows - reconstructed_np), axis=(1, 2))print(f"계산된 MAE 값 (처음 5개): {mae[:5]}")# 이상치 탐지를 위한 임계값 설정 (데이터 및 모델 성능에 따라 조정 필요)# 예: MAE의 평균 + (표준편차 * 특정 배수) 또는 분위수 사용threshold = np.mean(mae) +1.5* np.std(mae) # 표준편차 배수를 2에서 1.5로 줄여 민감도 증가print(f"이상치 탐지 임계값 (MAE): {threshold:.4f}")anomalies_indices_in_windows = np.where(mae > threshold)[0] # 윈도우 배열 내의 인덱스print(f"이상치로 탐지된 윈도우의 수: {len(anomalies_indices_in_windows)}")print(f"이상치로 탐지된 윈도우 인덱스: {anomalies_indices_in_windows}")# 윈도우 인덱스를 원본 데이터 인덱스로 대략적으로 매핑 (윈도우의 시작점 기준)# 실제 이상치 발생 시점과 정확히 일치하지 않을 수 있음anomalies_approx_original_indices = anomalies_indices_in_windows # 좀 더 정확하게는 윈도우의 중간 지점 등을 고려할 수 있으나, 여기서는 시작점으로 단순화# anomalies_approx_original_indices = [idx + window_size // 2 for idx in anomalies_indices_in_windows]print(f"원본 데이터의 대략적인 이상치 인덱스 (윈도우 시작점 기준): {anomalies_approx_original_indices}")