import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
import warnings
warnings.filterwarnings('ignore')안녕하세요 이번 포스트는 ABC 프로젝트 멘토링 8기 2주차 실습 기록입니다. 지난주엔 시계열 데이터 EDA랑 전처리만 했는데, 이번엔 간단한 머신러닝 모델로 이상치 탐지 기법을 소개하려 합니다.
Tip
이 포스트는 Week1 포스트에서 진행했던 데이터 준비/탐색 내용을 바탕으로, 실제 머신러닝 기반 이상 탐지 실습에 초점을 맞췄습니다.
1. 데이터 준비
np.random.seed(42)
t = np.arange(0, 100, 1)
y = np.sin(0.2 * t) + np.random.normal(0, 0.2, size=len(t))
# 여러 위치에 인위적으로 이상치 추가
outlier_indices = [15, 35, 55, 75, 90]
outlier_values = [2, -2, 2.5, -2.5, 3]
for idx, val in zip(outlier_indices, outlier_values):
y[idx] += val
df = pd.DataFrame({'time': t, 'value': y})plt.figure(figsize=(10,4))
plt.plot(df['time'], df['value'], label='시계열 데이터')
plt.scatter(df.loc[outlier_indices, 'time'], df.loc[outlier_indices, 'value'], color='red', label='부여한 이상값')
plt.legend()
plt.title('이상값이 포함된 시계열 데이터')
plt.show()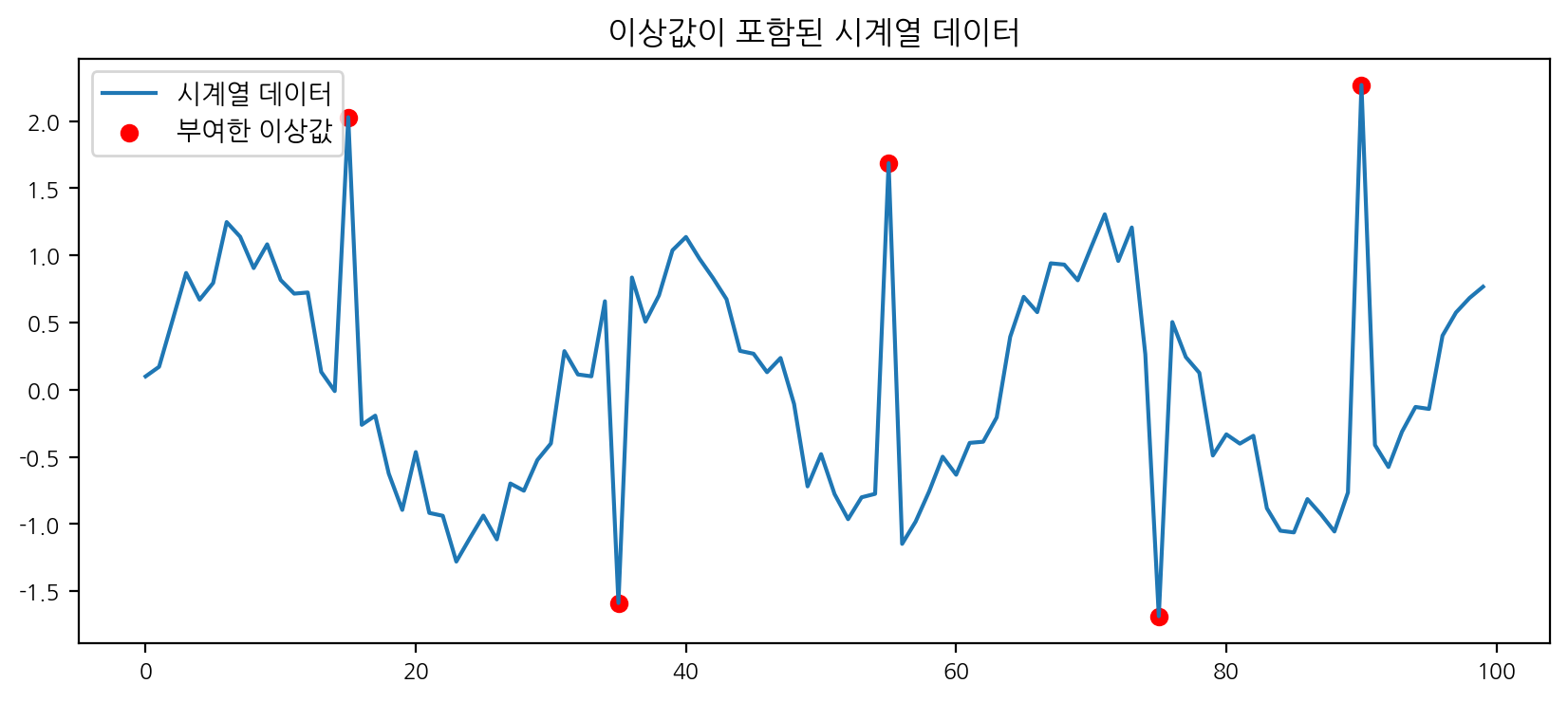
2. 머신러닝 기반 이상 탐지 (Isolation Forest, DBSCAN, One-Class SVM)
모델별 특징 및 한계
| 모델 | 장점 | 한계/주의점 |
|---|---|---|
| Isolation Forest | 대용량/고차원 데이터에 강함, 빠름 | 이상치 비율(contamination) 추정 필요 |
| DBSCAN | 군집/밀도 기반, 파라미터 직관적 | eps, min_samples에 민감, 1차원 한계 |
| One-Class SVM | 비선형 경계, 소규모 데이터에 적합 | 느릴 수 있음, 파라미터 튜닝 필요 |
Isolation Forest
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination=0.05, random_state=42)
df['anomaly_isof'] = model.fit_predict(df[['value']])plt.figure(figsize=(10,4))
plt.plot(df['time'], df['value'], label='시계열 데이터')
plt.scatter(df[df['anomaly_isof']==-1]['time'], df[df['anomaly_isof']==-1]['value'], color='red', label='탐지된 이상값')
plt.legend()
plt.title('Isolation Forest 기반 이상 탐지 결과')
plt.show()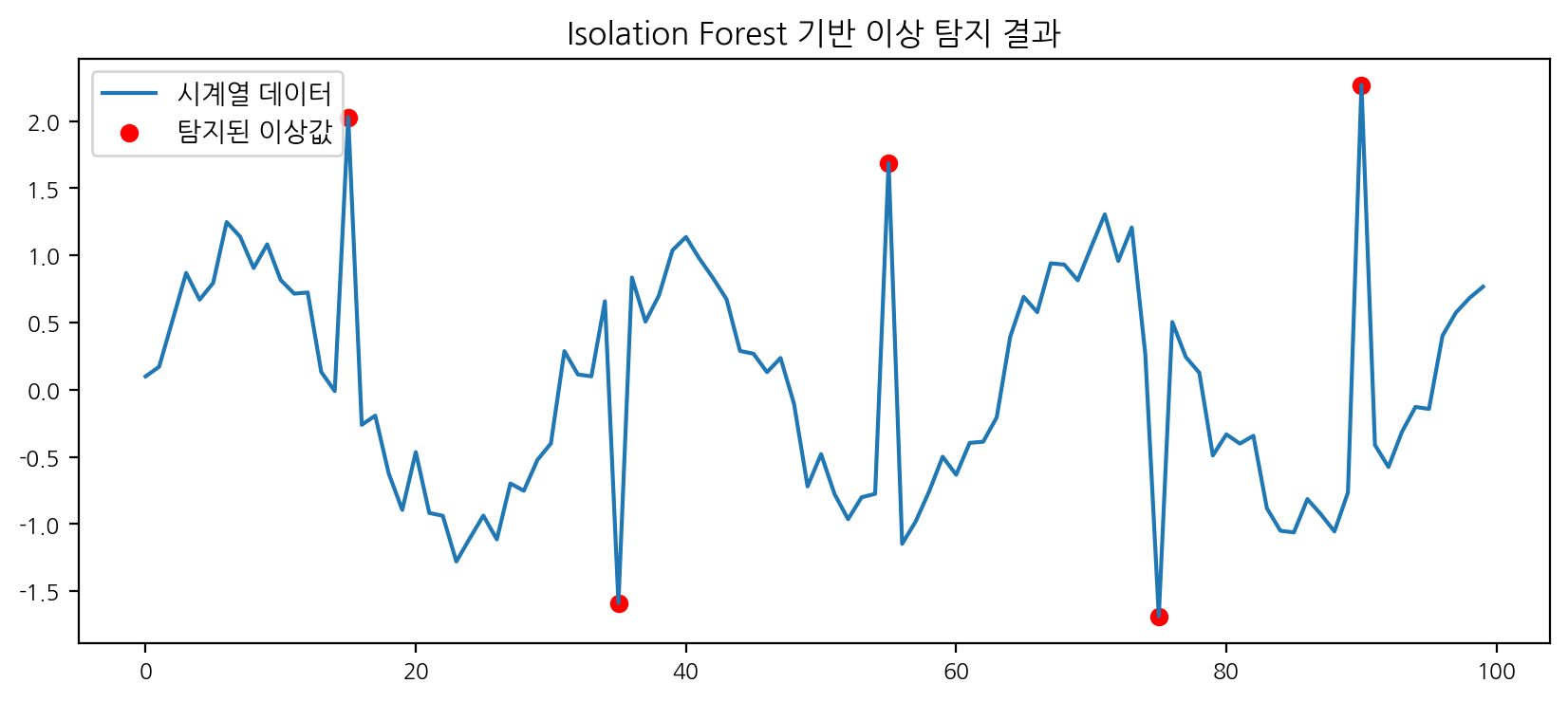
DBSCAN (밀도 기반 이상 탐지)
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df[['value']])
dbscan = DBSCAN(eps=0.25, min_samples=3) # eps와 min_samples를 조정해 민감도 조정
df['anomaly_dbscan'] = dbscan.fit_predict(X_scaled)plt.figure(figsize=(10,4))
plt.plot(df['time'], df['value'], label='시계열 데이터')
plt.scatter(df[df['anomaly_dbscan']==-1]['time'], df[df['anomaly_dbscan']==-1]['value'], color='orange', label='탐지된 이상값(DBSCAN)')
plt.legend()
plt.title('DBSCAN 기반 이상 탐지 결과')
plt.show()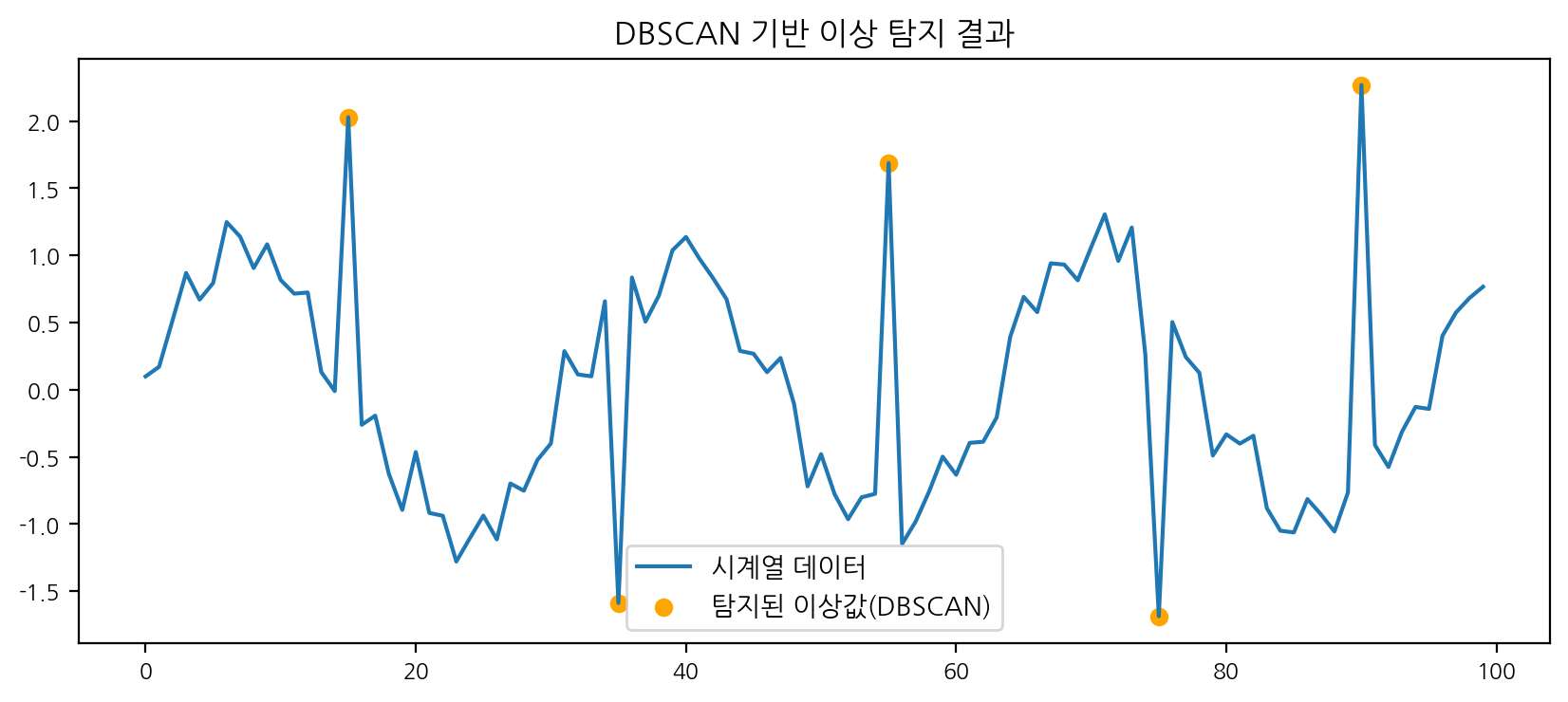
One-Class SVM (서포트 벡터 머신 기반 이상 탐지)
from sklearn.svm import OneClassSVM
# 기본 파라미터로는 이상치 탐지가 잘 안 됨 (F1이 0.14 수준)
ocsvm = OneClassSVM(nu=0.05, kernel='rbf', gamma='auto')
df['anomaly_ocsvm'] = ocsvm.fit_predict(df[['value']])plt.figure(figsize=(10,4))
plt.plot(df['time'], df['value'], label='시계열 데이터')
plt.scatter(df[df['anomaly_ocsvm']==-1]['time'], df[df['anomaly_ocsvm']==-1]['value'], color='purple', label='탐지된 이상값(OCSVM)')
plt.legend()
plt.title('One-Class SVM 기반 이상 탐지 결과')
plt.show()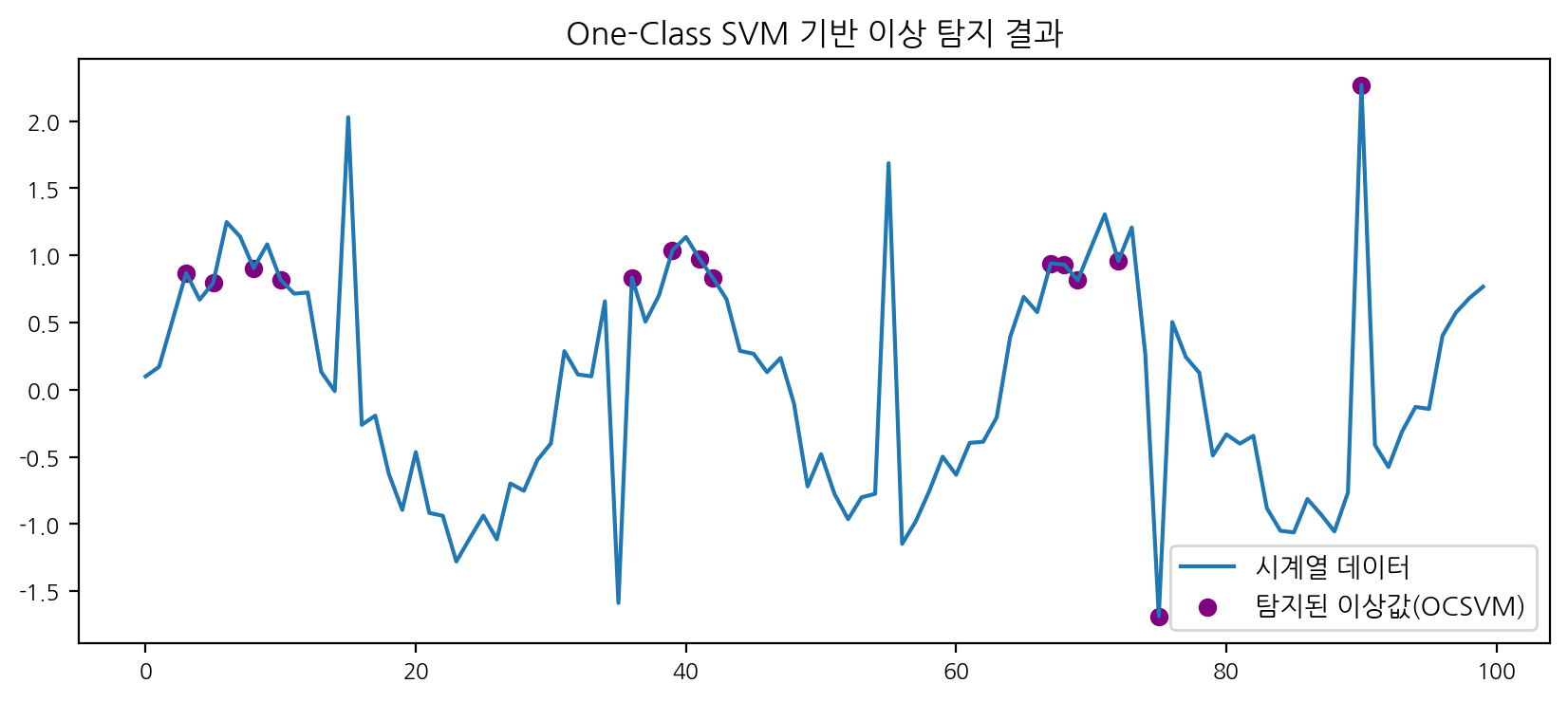
SVM 파라미터 튜닝 시도
# gamma 값을 더 크게, nu 값을 더 높게 조정해서 민감도를 높임
ocsvm_tuned = OneClassSVM(nu=0.12, kernel='rbf', gamma=2)
df['anomaly_ocsvm_tuned'] = ocsvm_tuned.fit_predict(df[['value']])plt.figure(figsize=(10,4))
plt.plot(df['time'], df['value'], label='시계열 데이터')
plt.scatter(df[df['anomaly_ocsvm_tuned']==-1]['time'], df[df['anomaly_ocsvm_tuned']==-1]['value'], color='blue', label='탐지된 이상값(튜닝 SVM)')
plt.legend()
plt.title('튜닝된 One-Class SVM 기반 이상 탐지 결과')
plt.show()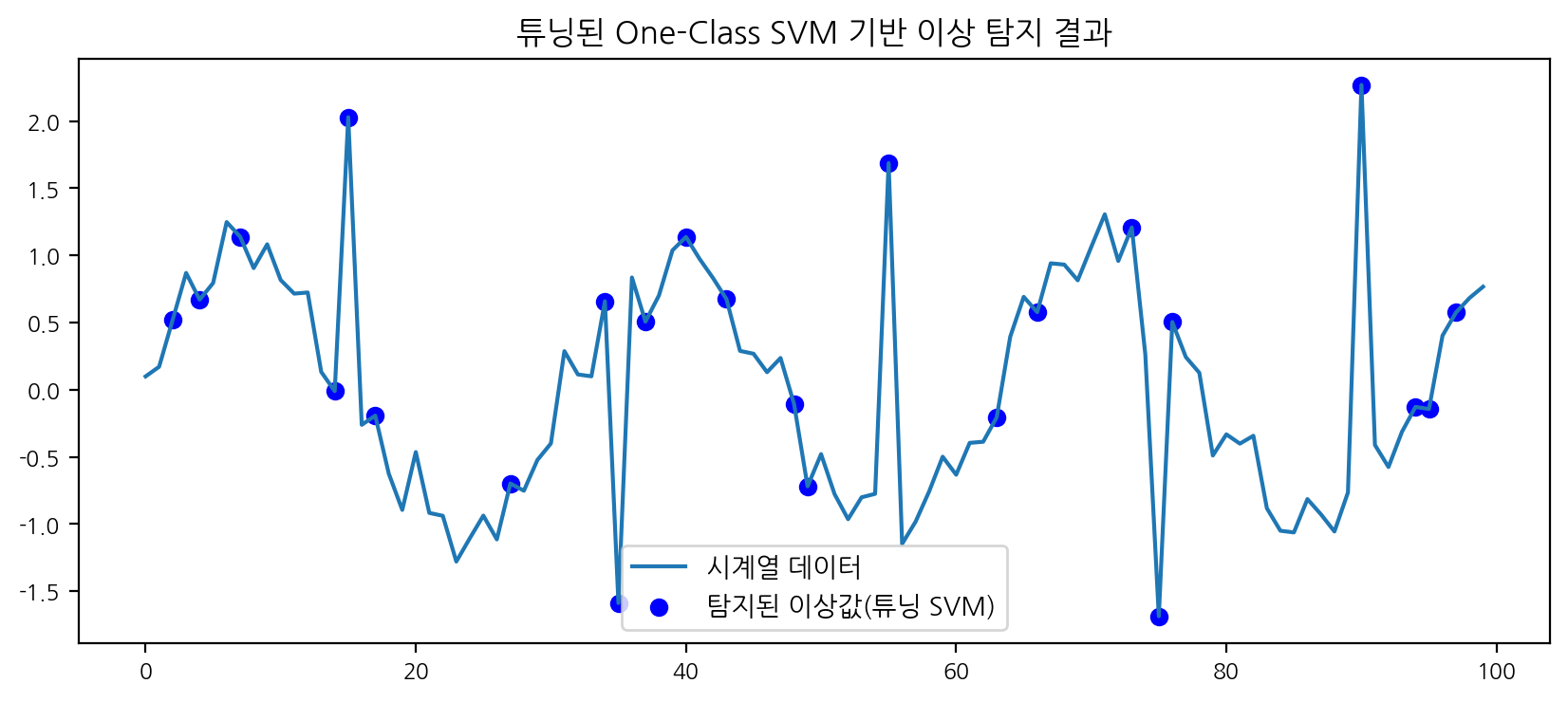
이상치 탐지 및 평가지표(Precision, Recall, F1)
from sklearn.metrics import precision_score, recall_score, f1_score
def anomaly_metrics(true_outliers, pred_outliers, n):
true = [1 if i in true_outliers else 0 for i in range(n)]
pred = [1 if i in pred_outliers else 0 for i in range(n)]
p = precision_score(true, pred)
r = recall_score(true, pred)
f1 = f1_score(true, pred)
return p, r, f1
n = len(df)
true_outliers = outlier_indices
pred_isof = df.index[df['anomaly_isof']==-1].tolist()
p_isof, r_isof, f1_isof = anomaly_metrics(true_outliers, pred_isof, n)
pred_dbscan = df.index[df['anomaly_dbscan']==-1].tolist()
p_dbscan, r_dbscan, f1_dbscan = anomaly_metrics(true_outliers, pred_dbscan, n)
pred_ocsvm = df.index[df['anomaly_ocsvm']==-1].tolist()
p_ocsvm, r_ocsvm, f1_ocsvm = anomaly_metrics(true_outliers, pred_ocsvm, n)
pred_ocsvm_tuned = df.index[df['anomaly_ocsvm_tuned']==-1].tolist()
p_ocsvm_t, r_ocsvm_t, f1_ocsvm_t = anomaly_metrics(true_outliers, pred_ocsvm_tuned, n)
print(f"Isolation Forest - Precision: {p_isof:.2f}, Recall: {r_isof:.2f}, F1: {f1_isof:.2f}")
print(f"DBSCAN - Precision: {p_dbscan:.2f}, Recall: {r_dbscan:.2f}, F1: {f1_dbscan:.2f}")
print(f"One-Class SVM - Precision: {p_ocsvm:.2f}, Recall: {r_ocsvm:.2f}, F1: {f1_ocsvm:.2f}")
print(f"튜닝 SVM - Precision: {p_ocsvm_t:.2f}, Recall: {r_ocsvm_t:.2f}, F1: {f1_ocsvm_t:.2f}")Isolation Forest - Precision: 1.00, Recall: 1.00, F1: 1.00
DBSCAN - Precision: 1.00, Recall: 1.00, F1: 1.00
One-Class SVM - Precision: 0.14, Recall: 0.40, F1: 0.21
튜닝 SVM - Precision: 0.21, Recall: 1.00, F1: 0.343. 결과 해석 및 정리
- One-Class SVM은 기본 파라미터로는 이상치 탐지가 잘 되지 않았으나, gamma와 nu를 조정해 튜닝하면 성능이 개선되는 것을 확인할 수 있다. 이 과정에서 파라미터 튜닝의 중요성을 경험했다.
- 각 모델별로 이상치 탐지 결과와 평가지표(Precision, Recall, F1)가 다르게 나타난다. Isolation Forest는 인위적으로 넣은 이상치를 대부분 탐지했고, DBSCAN은 파라미터에 따라 민감하게 반응한다. One-Class SVM은 데이터 분포와 파라미터에 따라 결과가 크게 달라진다.
- Precision(정밀도), Recall(재현율), F1-score는 모델의 이상치 탐지 성능을 종합적으로 평가하는 지표로, 실제 데이터 분석에서는 여러 방법을 비교하고 도메인 지식과 함께 해석하는 것이 중요하다.